#AI-基于Yolo的机器视觉自动瞄准
🤡5ea1
由于本文将同步作为我提交的论文,所以在格式上不能过于随意,故作调整😞
第一章 绪论
研究背景
第一节 技术背景
人工智能是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学,也是智能学科重要的组成部分,它企图了解智能的实质,并生产出一种新的能以与人类智能相似的方式做出反应的智能机器。
而Yolo是在该领域下机器视觉的新兴模型,打破了R-CNN系列算法的垄断,并在保证精确性的情况下大大加快的图像识别的速度。但由于Yolo系列算法并非专门团队开发,且其拥有着开源的属性,导致了Yolo的更新一直处于一种混乱的态势,使得各个版本的Yolo皆有其可取之处。
且自动瞄准这一项工程需要软件的实时性,这一点Yolo也能很好的胜任
第二节 应用背景
自动瞄准技术在市面上应用较少,主要还是应用于军用方面,现有的技术文章也较为稀少。实际设计可用于监控摄像头旋转,无人机拦截仪的瞄准等方面
研究目的
本研究聚焦于基于 Yolo 的自动瞄准系统开发,旨在解决传统瞄准技术在精准度、效率及智能化程度方面存在的局限性。通过整合先进的计算机视觉技术与目标检测算法,实现对特定目标的快速、精准自动定位与瞄准,以满足军事、安防、工业自动化等多领域对高精度瞄准系统的迫切需求。具体而言,研究目的包括以下几个方面:
第一节 实现高精度目标检测与定位
借助 Yolo 算法的高效性与准确性,对复杂场景中的目标进行实时检测,精确提取目标的位置信息(如坐标、边界框等),为后续的瞄准动作提供精准的数据支持。通过大量样本训练与算法优化,确保系统在不同光照、距离、遮挡等条件下,均能稳定且准确地识别目标,将目标定位误差控制在极小范围内,显著提升瞄准的精度水平。
第二节 达成快速实时瞄准响应
针对动态目标或时间敏感场景,设计并优化基于 Yolo 的自动瞄准系统架构,使其具备快速的数据处理能力与决策响应机制。通过硬件加速、算法并行化等手段,缩短从目标检测到瞄准指令生成的时间延迟,确保系统能够在极短时间内完成瞄准动作,有效捕捉高速移动目标或应对瞬息万变的态势,极大提高系统的实时性与动态适应性。
第三节 探索智能化瞄准控制策略
结合人工智能与机器学习技术,赋予自动瞄准系统自主学习与智能决策能力。除了基本的目标定位与瞄准功能外,研究如何使系统根据目标特性、环境变化及任务需求,自动调整瞄准参数,实现智能化的瞄准控制。例如,在多目标场景中,能够依据目标优先级自动切换瞄准对象;在受到干扰时,能够迅速调整瞄准策略以确保命中率,从而提升系统在复杂多变环境下的作战效能与可靠性。
研究意义
本研究在军事国防、安防监控、工业制造等多个领域均具有重要且深远的意义,为相关行业的技术升级与创新发展提供了有力支撑。
第一节 军事国防领域
提升作战效能
在现代战争中,精确打击能力是决定胜负的关键因素之一。基于 Yolo 的自动瞄准系统能够极大提高武器装备的瞄准精度与打击速度,无论是在空战、海战还是陆战场景中,均可实现对敌方目标的快速、精准锁定与摧毁,显著提升作战部队的火力打击效能与战场生存能力。
减少人员伤亡风险
自动瞄准系统的应用可使作战过程更加自动化与智能化,减少对人工操作的依赖,从而降低士兵在前线面临的危险。特别是在高风险作战任务(如排爆、反恐突袭等)中,能够实现远程精确瞄准与打击,最大限度保障作战人员的生命安全。
推动军事智能化进程
本研究是军事智能化技术发展的重要组成部分,为未来无人作战系统、智能武器平台等的研发奠定了坚实基础。通过探索基于深度学习的自动瞄准技术,促进军事技术向自主化、智能化方向迈进,有助于重塑现代战争形态与作战模式,提升国家军事战略竞争力。
第二节 安防监控领域
增强边境管控与反恐能力
在边境安防、重要设施保卫及反恐斗争中,快速准确地识别与瞄准潜在威胁目标至关重要。基于 Yolo 的自动瞄准系统可集成于监控摄像头、无人机等安防设备中,实现对非法越境人员、可疑车辆、恐怖分子等目标的实时监测与自动锁定,为安保人员提供及时准确的预警信息与精确打击支持,有效提升国家边境安全与社会稳定保障水平。
助力智能安防体系建设
随着智慧城市概念的普及,安防监控系统正朝着智能化、自动化方向快速发展。本研究成果可促进智能安防技术的创新应用,实现安防监控从传统的人工值守向智能自动预警与处置转变。通过与大数据分析、云计算等技术的融合,构建全方位、多层次的智能安防体系,提高城市公共安全管理的效率与科学性,为居民创造更加安全和谐的生活环境。
研究的难点和创新点
本研究的难点在于
- 研究和训练环境与实际应用场景差异较大,在实际应用场景中,环境因素极为复杂多变,这对基于 Yolo 的自动瞄准系统的目标识别与定位能力构成了严峻挑战。例如,在光照条件不佳(如强光直射、阴影遮挡、低光照夜晚等)的情况下,目标的外观特征可能发生显著变化,导致 Yolo 算法难以准确提取有效的特征信息进行识别。
- Yolo系统本身的一些缺陷,由于每一代Yolo的源码都适配的是更新者所在的项目,其预处理和后处理参数不一定与此研究所要的参数符合,训练和调用效果会大打折扣。
- 不同Yolo算法下的效率和精确性大有不同,选择合适的算法也是一大难点
本研究的创新点在于
- 在训练时使用了Yolo-v9的算法,以提高获得的pt模型检测时的精确性。而在检测时重写了检测脚本,以Yolo-v5lite的检测思路为大纲,去除了不必要的处理部分,大大提升了检测脚本的实时性。
- 通过调节Yolo中的最大抑制阈值和最大置信度,使得训练出的模型更能适应实际环境的不确定性和复杂性。
- 为了简化对大量图片的切片上标签处理,设计了一个全新的自动化标签处理器,可以轻松创建数据集。
- 通过计算瞄准点和当前点的动态关系,提前推断要进行的操作,来提高效率,避免不必要的多余操作。
研究方法
静态分析代码
通过单段调试,交叉应用等方法静态分析代码逻辑,优化代码本身。
动态模拟项目
通过播放视频或在仿真游戏中模拟实际环境,观察研究项目的表现。
第二章 自动瞄准系统设计概述
系统主要分为数据集制作、训练模型、检测应用三大部分
数据集制作
数据收集
针对自动瞄准系统的应用场景,广泛收集相关的图像或视频数据。例如在军事应用中,收集不同地形、天气、光照条件下各类目标(如敌方装备、人员等)的素材;在安防领域,采集监控场景下的行人、车辆等数据;对于工业应用,则收集生产线上的零部件、产品等图像资料。数据来源可以包括公开的图像数据库、实地拍摄以及模拟场景生成的数据等,以确保数据的多样性和全面性。
此处我选择了从视频平台中选择了一段视频,通过脚本获取其中每一帧的图像,再对图像进行了裁剪和压缩,使每一张图像都被修改为864*540大小(原图像的等比例缩小),来和我在Yolo算法中设定的640像素大小的数据窗口拟合
数据标注
对收集到的数据进行精确标注,这是数据集制作的关键环节。对于图像数据,需要标注出目标的类别(如飞机、坦克、行人等)以及目标在图像中的位置信息,通常采用边界框(bounding box)标注的方式,即确定目标的左上角和右下角坐标,或者标注目标的中心坐标及宽高信息。
由于数据量巨大,此处采取了自动化标注的方法,由于技术限制,我选择了Yolo自带的Coco预处理权重辅助标注。
数据预处理
为了提高数据的质量和模型训练的效率,对标注好的数据进行预处理。这包括图像的裁剪、缩放、旋转、色彩调整等操作,使数据具有统一的尺寸和格式,并且能够突出目标特征。同时,还可以进行数据增强处理,如随机翻转、添加噪声等,通过增加数据的多样性来提高模型的泛化能力,避免模型过拟合。经过预处理后的数据将被整理成适合模型训练的数据集格式,如按照一定比例划分为训练集、验证集和测试集,以便在不同阶段对模型进行评估和优化。
Yolo算法要求数据集分为test、train、val三块,在这个项目中我选择了2:7:1的方式安排这三块数据集的数据规模,来确保训练效果最大化。还需要对数据进行裁剪、缩放、旋转、色彩调整来强化训练
训练模型
模型选择与搭建
此处为了确保较高的精确度,且考虑到设备性能较高,选择了Yolo-v9来作为主模型。在 COCO 数据集上,Yolo-v9的 mAP 指标达到新高度,超越了前一代 YOLOv8 和其他同类目标检测算法。在处理小目标和复杂场景中的目标时,能更精准地捕捉目标细节信息,鲁棒性更强,更加适合用于这样追求精确度的项目。且该版本的算法引入了自适应学习率调整策略,能够根据训练过程中的情况自动调整学习率,使模型训练更加稳定,加快收敛速度,减少训练时间。
训练过程
将制作好的训练集数据输入到搭建好的模型中进行训练。训练过程中,模型根据输入图像数据和对应的标注信息,通过前向传播计算预测结果(目标类别和位置),然后与真实标注进行对比,计算损失函数(如交叉熵损失用于分类,均方误差损失用于定位等)。利用反向传播算法,根据损失函数的值来调整模型的参数(权重和偏差),以最小化损失函数,使得模型的预测结果逐渐逼近真实情况。训练过程通常需要大量的计算资源和时间,并且需要设置合适的训练参数,如学习率、迭代次数、批处理大小等。学习率控制模型参数更新的步长,迭代次数决定了模型训练的轮数,批处理大小则影响每次参数更新的样本数量。在训练过程中,还需要定期在验证集上评估模型的性能,如计算准确率、召回率、平均精度均值(mAP)等指标,以便及时发现模型是否出现过拟合或欠拟合等问题,并对训练参数进行调整。
模型优化与保存
即后处理操作,在本项目中仅对置信度和NMS参数作了修正
检测应用
图像采集与输入
在本项目中包含了三种采集图像方法,即摄像头采集、屏幕捕获和批量图片检测,可以在代码中进行切换。
目标检测与定位
由于Yolo-v9的检测部分运行缓慢,此项目选择了Yolo-v5lite的检测部分与之耦合,来加快检测速度
瞄准决策与执行
由于设备的局限性,此项目中将瞄准决策行为与鼠标移动行为化等,且依次用视频和游戏来对项目作测试,前者不限制移动速率,而后者则应当同时考虑移动策略,限制单次移动行为。
第三章 创新自动化数据集制作
在该项目中此操作被分为6步,截取帧图片,转换图片大小,检测图片加标签,标签筛选,无关数据删除和分配创建数据集
截取帧图片
在本项目中采用了cv2库和os库,直接读取了对应视频并从中获取每一帧的图像,以序号为名输出至选定的数据文件夹下,此处的路径可以由字符串拼接而成
while True:
h=h+1
rval, frame = cv.read()
if h == fps:
h = 0
order = order + 1
if rval:
cv2.imwrite('./cs_2/images/' + str(order) + '.jpg', frame) #图片保存位置以及命名方式
cv2.waitKey(1)
print("success!",str(order),".jpg")
else:
break
转换图片大小
使用了os库和PIL库,遍历数据文件夹,将其中每一张图片修改为需要的像素大小,并输出
def resize_images_in_folder(input_folder, output_folder, new_width, new_height):
# 遍历输入文件夹中的所有文件
i=0
for filename in os.listdir(input_folder):
if filename.endswith(".jpg") or filename.endswith(".png"):
# 构建输入和输出文件的路径
input_image_path = os.path.join(input_folder, filename)
output_image_path = os.path.join(output_folder, filename)
# 调用resize_image函数修改图片分辨率
resize_image(input_image_path, output_image_path, new_width, new_height)
print("success!",filename)
else:
print("Defeat!",filename)
检测图片加标签
这一部分使用了Coco和预处理权重辅助检测,即
parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'weights/yolov9-e-converted.pt', help='model path or triton URL')
检测部分代码为保证精确性直接使用了Yolo-v9自带的检测代码。由于代码本体不会输出标签,所以要加以修改。检索代码,发现检测过程中包含一块txt输出块,但是条件部分有讹漏,不能正确的跳入输出中,故将134行左右代码条件修改
for *xyxy, conf, cls in reversed(det):
if 1: # Write to file
xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
line = (cls, *xywh, conf) if save_conf else (cls, *xywh) # label format
with open(f'{txt_path}.txt', 'a') as f:
f.write(('%g ' * len(line)).rstrip() % line + '\n')
if save_img or save_crop or view_img: # Add bbox to image
c = int(cls) # integer class
label = None if hide_labels else (names[c] if hide_conf else f'{names[c]} {conf:.2f}')
annotator.box_label(xyxy, label, color=colors(c, True))
if save_crop:
save_one_box(xyxy, imc, file=save_dir / 'crops' / names[c] / f'{p.stem}.jpg', BGR=True)
并在前面按照输出图片的地址格式重写一个txt地址,使得最后会输出一个label文件夹,和image文件夹同目录。运行后将获取一个拥有标签的图片数据集
标签筛选
由于Coco.yaml的文件内容已知,可以清晰的知道检测出的标签中,特征数字对应的物体名称,所以在该项目中仅需查找标签中对应的特征数字即可,再删去多余的数字。Yolo中标签由5个数字组成,第一个数字是特征数字,后面几个数字指示着该标签的框在图片中的位置。
此脚本的逻辑即先查找特征数字,若未找到,将该文件删除,若找到了,则保留该行,但删除其他无关行
import os
import shutil
# 指定特殊标签
special_label = "0"
# 指定文件夹路径,你需要将这里替换为实际的文件夹绝对路径
folder_path = "C:/Users/seal/Yolo/yolov9-main1/yolov9-main/runs/detect/exp26/labels/"
# 指定目标文件夹路径,用来存放符合条件的文件,若不存在会自动创建
target_folder_path = "C:/Users/seal/Yolo/yolov9-main1/yolov9-main/runs/find/cs_2"
files_with_label = []
def del_file(filepath):
"""
删除某一目录下的所有文件或文件夹
:param filepath: 路径
:return:
"""
del_list = os.listdir(filepath)
for f in del_list:
file_path = os.path.join(filepath, f)
if os.path.isfile(file_path):
os.remove(file_path)
if not os.path.exists(target_folder_path):
os.mkdir(target_folder_path) # 创建文件夹
else:
del_file(target_folder_path) # 清空文件夹
s1=0
s2=0
s3=0
s4=0
n=0
x=0
# 遍历文件夹下所有文件
for root, dirs, files in os.walk(folder_path):
for file in files:
if file.endswith('.txt'):
file_path = os.path.join(root, file)
flag=0
text=""
with open(file_path, 'r') as f:
lines = f.readlines()
for line in lines:
parts = line.strip().split() # 按空格分割每行内容,得到参数列表
#含有特定的labels
if len(parts) == 5 and parts[0] == special_label:
target_file_path = os.path.join(target_folder_path, file)
print("success!",file_path.strip().split('/')[-1])
new_line = " ".join(parts) + "\n"
text+=new_line
flag=1
if flag==0:
files_with_label.append(file_path)
x+=1
else:
with open(target_file_path,"w+") as f_write:
f_write.write(text)
在该脚本中给出了对含有特定的labels的文件进行筛选的方法,运行后会将修改后的labels文件重新整合到指定文件夹中
无关数据删除
上面脚本运行后标签文件被修改,但是图像集并未被改动,为了保证不发生错误,会使用上脚本中输出的无关数据名字,借助输出的名字加上字符串操作,即可拼合出其对应图片的路径,辅助删除
import os
files_with_label = []#此处填写上文中输出的txt文件名集合
paths = "/images/"
for file_path in files_with_label:
parts=file_path.strip().split('/')
unity="".join(parts[-1])
parts1=unity.strip().split('.')
file_path=str(paths + parts1[0]+".jpg")
try:
os.remove(file_path)
print(f"已成功删除文件: {file_path}")
except FileNotFoundError:
print(f"文件 {file_path} 不存在,无法删除")
except PermissionError:
print(f"没有权限删除文件 {file_path}")
except OSError as e:
print(f"删除文件 {file_path} 时出现其他错误: {e}")
分配创建数据集
按照7:2:1的比例进行分割,随机分配,再依次放入train,test,val文件夹内
关键分割部分脚本如下
train, val, test = split_list
all_img = os.listdir(img_path)
all_img_path = [os.path.join(img_path, img) for img in all_img]
# all_label = os.listdir(label_path)
# all_label_path = [os.path.join(label_path, label) for label in all_label]
train_img = random.sample(all_img_path, int(train * len(all_img_path)))
train_img_copy = [os.path.join(train_img_dir, img.split('\\')[-1]) for img in train_img]
train_label = [toLabelPath(img, label_path) for img in train_img]
train_label_copy = [os.path.join(train_label_dir, label.split('\\')[-1]) for label in train_label]
for i in tqdm(range(len(train_img)), desc='train ', ncols=80, unit='img'):
if os.path.exists(train_label[i]):
_copy(train_img[i], train_img_dir)
_copy(train_label[i], train_label_dir)
all_img_path.remove(train_img[i])
val_img = random.sample(all_img_path, int(val / (val + test) * len(all_img_path)))
val_label = [toLabelPath(img, label_path) for img in val_img]
for i in tqdm(range(len(val_img)), desc='val ', ncols=80, unit='img'):
if os.path.exists(val_label[i]):
_copy(val_img[i], val_img_dir)
_copy(val_label[i], val_label_dir)
all_img_path.remove(val_img[i])
test_img = all_img_path
test_label = [toLabelPath(img, label_path) for img in test_img]
for i in tqdm(range(len(test_img)), desc='test ', ncols=80, unit='img'):
if os.path.exists(test_label[i]):
_copy(test_img[i], test_img_dir)
_copy(test_label[i], test_label_dir)
if __name__ == '__main__':
img_path = ''# 你的图片存放的路径(路径一定是相对于你当前的这个脚本文件而言的)
label_path = ''# 你的txt文件存放的路径(路径一定是相对于你当前的这个脚本文件而言的)
split_list = [0.7, 0.2, 0.1] # 数据集划分比例[train:val:test]
split_img(img_path, label_path, split_list)
至此,本项目的数据集制作完毕
第四章 创新检测脚本
原检测脚本主要侧重于按照命令行参数配置好的模式完整地执行从输入源数据加载、模型推理到结果展示及保存这一整套流程,更专注于一次性完整地完成目标检测任务。为了实现项目需要的功能,代码还需要更强的交互性和更快的检测速度,所以我对其进行了一系列改进,主要包含启动界面,快捷键启动暂停功能,简化检测和内嵌同步自动瞄准
启动界面
主要用于提升人机交互性,为了简化检测代码主体,将其放置在外部,作为库引入
class MySplashScreen(QSplashScreen):
def __init__(self):
super(MySplashScreen, self).__init__()
# 新建动画
self.movie = QMovie(r'C:\\Users\\seal\\Yolo\\yolov9-main\\yolov9-main\\gif\\dance2.gif')
self.movie.frameChanged.connect(lambda: self.setPixmap(self.movie.currentPixmap()))
self.movie.start()
def mousePressEvent(self, QMouseEvent):
pass
class LoadDataWorker(QObject):
finished = pyqtSignal()
message_signal = pyqtSignal(str)
def __init__(self):
super(LoadDataWorker, self).__init__()
def run(self):
for i in range(100):
time.sleep(0.05)
if(i==41+int(random()*10) or i==71+int(random()*10)):
time.sleep(1)
self.message_signal.emit(f'加载中...{str(i)}%')
self.finished.emit()
class Form(QMainWindow):
def __init__(self, splash):
super(Form, self).__init__()
self.resize(800, 600)
self.splash = splash
self.load_thread = QThread()
self.load_worker = LoadDataWorker()
self.load_worker.moveToThread(self.load_thread)
self.load_thread.started.connect(self.load_worker.run)
self.load_worker.message_signal.connect(self.set_message)
self.load_worker.finished.connect(self.load_worker_finished)
self.load_thread.start()
while self.load_thread.isRunning():
QtWidgets.qApp.processEvents()
self.load_thread.deleteLater()
def load_worker_finished(self):
self.load_thread.quit()
self.load_thread.wait()
def set_message(self, message):
self.splash.showMessage(message, Qt.AlignLeft | Qt.AlignBottom, Qt.white)
该脚本通过导入外部gif,在代码运行时获取代码进程名称,赋上断点,创建一个新窗口播放启动动画,并显示加载进度

快捷键启动暂停
创建一个键盘监听进程即可,若按下F10则启动,F12则暂停
def on_press(key):
global is_paused, is_resumed
if key == pynput.keyboard.Key.f12:
is_paused = True
is_resumed = False
print("程序已暂停,按下F10键恢复")
elif key == pynput.keyboard.Key.f10:
is_paused = False
is_resumed = True
print("程序已恢复运行")
内嵌同步自动瞄准
通过计算已知两点间的坐标差值,其比例可用作确定方向,用勾股定理算出长度,存入数组中,两两做差即可获取一系列目标相对运动的数据,再对其进行推测,控制设备进行瞄准
def predict_next_direction():
if len(relative_movement_data) < 2:
return 0, 0
dx_values = [data[0] for data in relative_movement_data]
dy_values = [data[1] for data in relative_movement_data]
# 使用numpy的polyfit进行一次多项式拟合(即线性拟合)
fit_dx = np.polyfit(np.arange(len(dx_values)), dx_values, 1)
fit_dy = np.polyfit(np.arange(len(dy_values)), dy_values, 1)
# 根据拟合结果预测下一个数据点对应的坐标差值
next_dx = np.polyval(fit_dx, len(dx_values))
next_dy = np.polyval(fit_dy, len(dy_values))
return next_dx, next_dy
def predict_and_move_mouse():
next_dx, next_dy = predict_next_direction()
if next_dx is not None and next_dy is not None:
mouse = Controller()
current_x, current_y = mouse.position
new_x = current_x + next_dx
new_y = current_y + next_dy
mouse.position = (new_x, new_y)
time.sleep(0.01)
while True:
predict_and_move_mouse()
time.sleep(0.1)
这个脚本使用最小二乘法预测下一个数据点的方向,这里以x和y方向的坐标差值作为拟合数据,预测下一个差值,来提前推断目标方向
第五章 实际训练与运用
训练结果
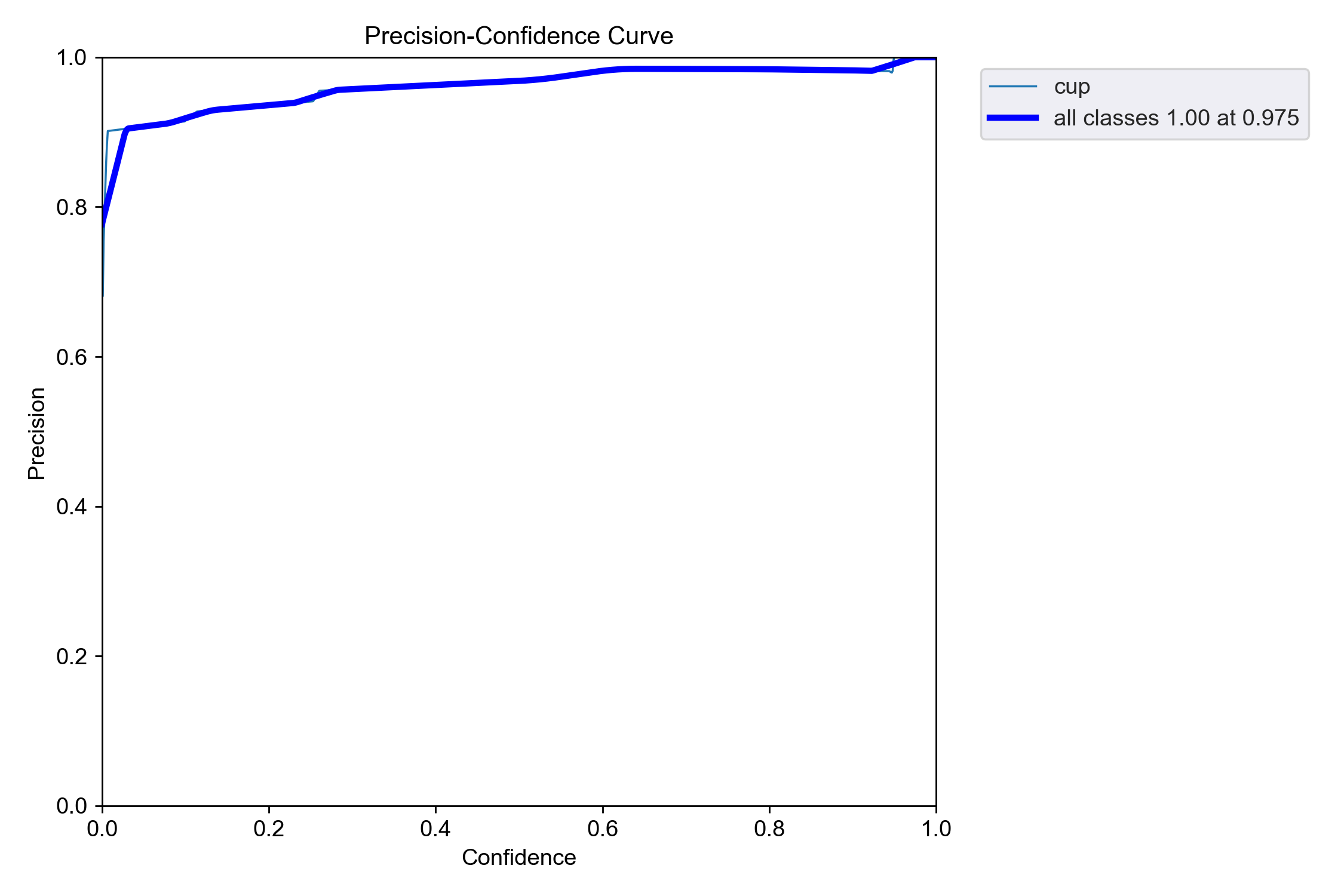
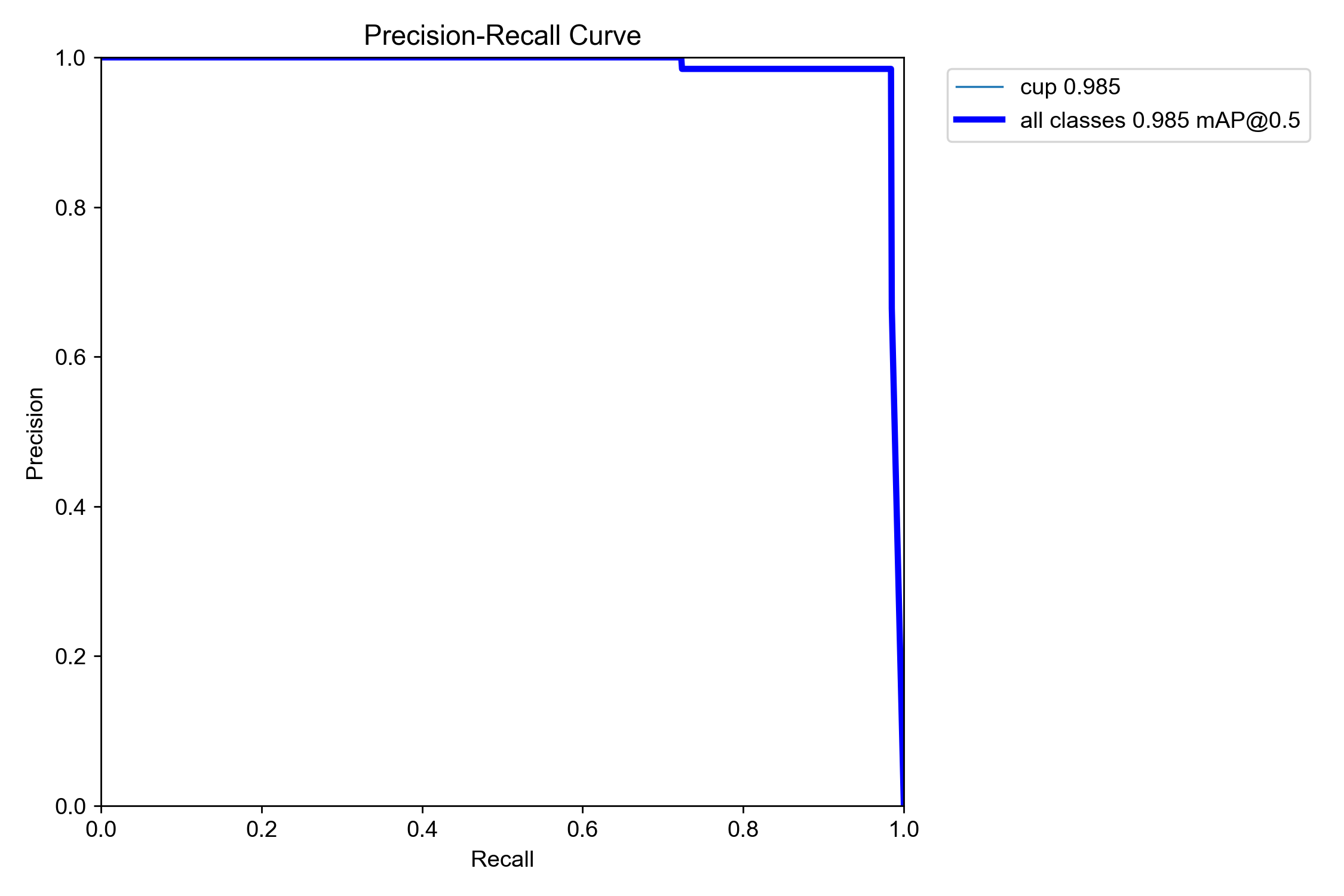
经过9000张图片的数据集300次训练后,可见图像中峰值已经很明显了,且P线,R线,PR线均接近于1,说明训练效果较好
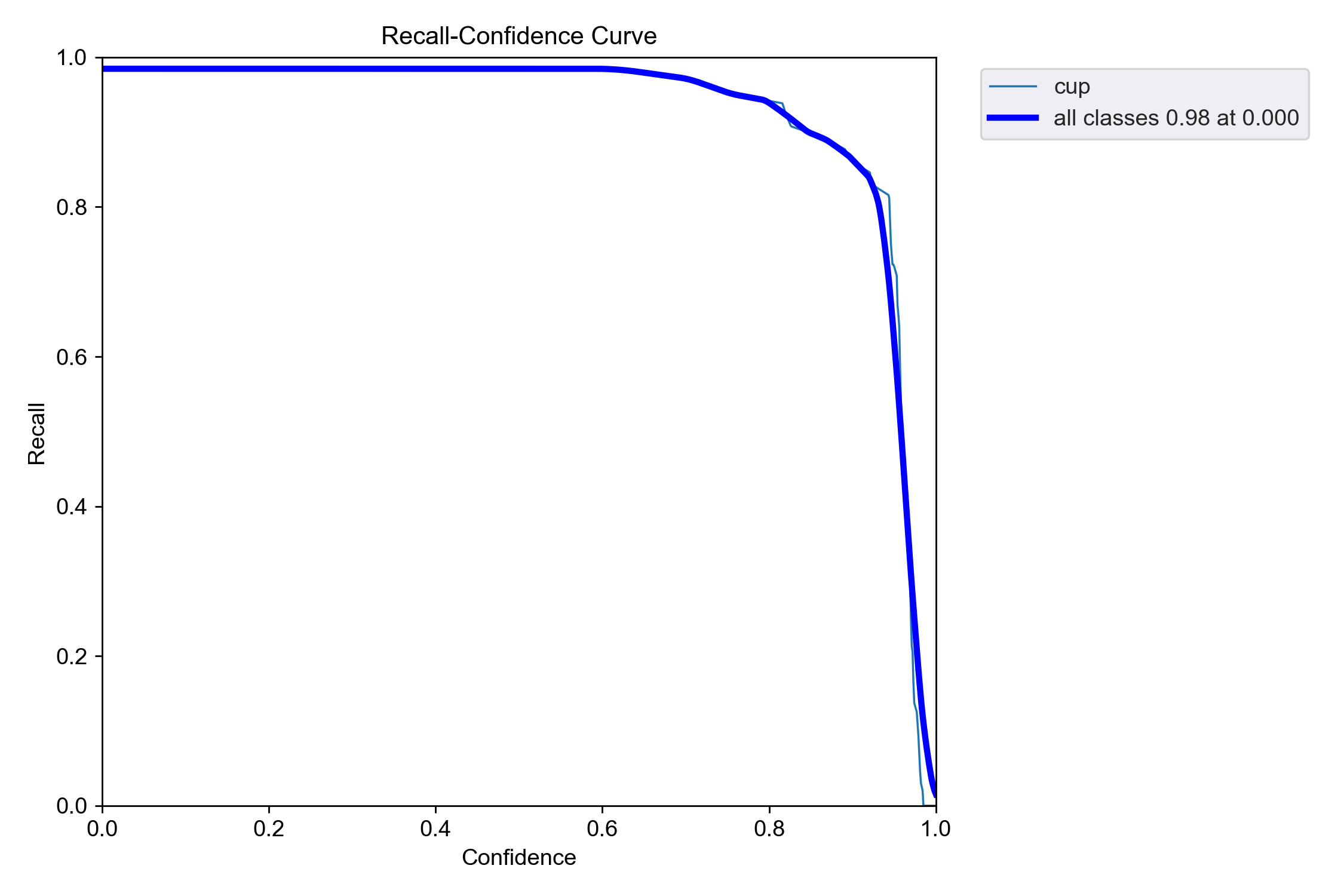
R-curve
R线即Recall(召回率)曲线,召回率是衡量模型在检测目标时能够正确找到所有正例的能力的指标。它的计算公式为:召回率 = 真正例 / (真正例 + 假负例),其中真正例即模型正确预测为正例的样本数量;假负例即实际为正例但被模型错误预测为负例的样本数量。通过在不同的置信度阈值下计算召回率,将这些召回率值与对应的置信度阈值绘制成曲线,就得到了召回率曲线。
召回率曲线能够直观地反映出模型在不同置信度水平下对正例的召回能力。曲线越高,说明模型在相同置信度阈值下能够召回更多的正例,即模型对正例的检测能力越强。此处可见该模型权重召回率相当高
P-curve
P线即Precision(精确率)曲线,精确率用于衡量模型预测正例的准确性。它的计算公式为:真正例/(真正例+假正例),其中的真正例为预测为正例且实际也为正例的样本数,假正例为预测为正例但实际为负例的样本数。
精确率曲线通过将不同置信度阈值下的精确率进行可视化展示,能够让用户直观地看到随着置信度阈值的调整,模型精确率的变化趋势。在比较多个不同的目标检测或图像识别模型时,精确率曲线可作为重要的对比依据。通过绘制不同模型的精确率曲线,可直观地看出各模型在不同阈值下的精确率高低,从而选择性能更优的模型。
PR-curve
Precision-Recall 曲线 通过在不同的置信度阈值下分别计算精确率和召回率,将得到的多组精确率和召回率数据绘制成曲线。通常以召回率为横轴,精确率为纵轴。该条曲线更为客观全面展示一个模型
实际运用
可维持60帧稳定运行,检测中距离以内物体快速准确,远距离物体准确率有所下降
第六章 改进方法
需要选用更高的像素参数来保证远距离下的检测,较高的像素参数能够捕捉到更多关于远距离目标的细节信息。在远距离场景中,目标在图像中所占的面积相对较小,较低像素的图像可能会导致目标的特征模糊不清,使得模型难以准确地识别和定位目标。而当采用更高像素参数时,图像的分辨率得到显著提高,即使是远距离目标的细微特征,如轮廓、纹理等,也能够更加清晰地呈现。这有助于目标检测模型更精准地提取目标特征,从而提升对远距离目标检测的准确性。
从模型训练的角度来看,更高像素参数的图像数据能够增强模型对远距离目标特征的学习能力。在训练过程中,丰富的像素信息可以促使模型更好地理解不同距离下目标特征的变化规律,从而提高模型的泛化能力,使其在面对实际远距离检测任务时表现得更加稳健和高效。
以下是我个人的设计
多尺度特征提取网络
设计一种专门的多尺度特征提取网络架构,该架构基于深度卷积神经网络(如 ResNet 或 VGG 等经典网络结构)进行改进。在网络的不同深度层次设置多个分支,用于提取不同尺度的特征图。例如,在网络的浅层提取低层次的纹理、边缘等细节特征,这些特征对于小目标的初步定位具有重要作用;在网络的深层提取高层次的语义特征,有助于对目标进行准确分类。通过这种方式,能够充分利用图像中不同尺度的信息,为远距离目标检测提供更全面的特征表示。
第七章 总结
在本次人工智能目标检测自动瞄准项目的实践过程中,我收获颇丰,不仅对相关技术有了更深入的理解和掌握,也在项目推进过程中积累了宝贵的经验,同时也清晰地认识到项目现存的不足以及未来可提升的方向。
项目成果概述
本项目旨在构建一个能够实现目标检测并自动瞄准的人工智能系统。通过对大量图像和视频数据的学习与训练,系统已具备在多种场景下检测特定目标的能力,并能依据检测结果进行自动瞄准操作。在实际测试中,项目展现出了一定的性能水平,能够较为准确地识别出目标物体的位置、类别等关键信息,并驱动瞄准装置做出相应的响应动作,在一些特定应用场景下已经能够初步发挥作用
技术亮点与学习收获
目标检测算法优化
深入研究了多种目标检测算法,并针对项目需求对算法进行了优化调整。通过调整网络结构、超参数设置以及数据增强策略等手段,提高了算法对不同尺度目标、复杂背景下目标以及遮挡目标的检测能力。在这个过程中,我不仅熟练掌握了这些经典算法的原理和实现细节,更学会了如何根据实际问题对算法进行灵活的定制和优化,深刻理解了算法中各个组件之间的相互关系和协同工作机制。
数据处理与标注技巧
数据是人工智能项目的核心基础,在本项目中,我从手动标注到了自动化标注,自己写了脚本辅助标注,大大提升了数据处理的效率,也学到了很多
项目不足之处
检测精度有待提升
尽管项目目前已能达到一定的检测性能,但在面对一些极端情况或高要求场景时,检测精度仍存在明显不足。比如说对于远距离目标的检测,误检率和漏检率相对较高;在目标快速运动或处于复杂光照条件下时,检测框的定位不够精准,容易出现漂移现象。这主要是由于当前算法在处理小目标特征提取时不够充分,以及在应对复杂动态环境时模型的适应性和鲁棒性不足所致。
稳定性和可移植性较低
该项目中的路径相对混乱,且环境于本机适配,并未额外制作兼容性,导致可移植性和稳定性都较差